论文:DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients
论文地址:https://arxiv.org/abs/1606.06160
代码地址:DoReFa-Net: Github
这篇论文可以看作是相对于BNN,尤其是XNOR-Net的进一步研究。在XNOR-Net以及一系列的BNN中,仅仅是将前向传播进行了量化,但是在反向传播的时候依旧是全精度的浮点数,也就是量化只对inference阶段有益,training阶段仍然需要全精度浮点数。这样会产生两个问题:
- 大型网络二值化之后的training阶段只能在算力高的机器上,不能直接在移动设备上进行training。
- 训练网络的时候大多数的计算以及时间开销都在backward阶段。
所以针对BNN网络还存在的问题,DoReFa提出了新的解决办法,需要关注的新特性为两点:
- 泛化了BNN的量化算法,使得weights、activations、gradients都可以被量化为任意bit。
- Backward过程也可以被量化,从而缩小backward的计算时长。
量化算法
基础表示
文章中的量化算法有一个非常重要的前提:fix-point。只有是定点小数才能应用文章提出来的量化算法。基于此假设,文章中将数字表示为以下形式:
\[\mathbf{x} = \sum_{m=0}^{M-1} c_m(\mathbf{x}) 2^m, \mathbf{y} = \sum_{k=0}^{K-1} c_k(\mathbf{y})2^k\] 其中\((c_n(·))_{n=0}^{N-1}\)是bit vector,按照二进制转化十进制的方式让bit vector与$2^m$以及$2^k$相乘。根据这样的表示,我们可以得到类似于XNOR-Net的点积计算(这里可以查看 XNOR-Net文章中的单比特量化操作,回忆一下$bitcount$的计算过程):
\[\mathbf{x}· \mathbf{y} = \sum_{m=0}^{M-1} \sum_{k=0}^{K-1} 2^{m+k} bitcount[and(c_m(\mathbf{x}), c_k(\mathbf{y}))], \\ c_m(\mathbf{x})_i, c_k(\mathbf{y})_i \in \{0,1\} \forall i, m, k\] 这样一次点积的计算复杂度为$O(MK)$,与$\mathbf{x}, \mathbf{y}$的长度成正比。这样对fix-point数的表示是整体运算的基础。既然有了量化的基础,就需要看在forward和backward过程之中如何应用上述的计算方式达到将定点数量化为任意bitwidth。
对于fix-point的量化非常重要,因为相比于BNN和8bit整型,fix-point是小数,因此这种量化算法可以直接应用到梯度的量化上。
Forward过程
文章中提到了“Straight Through Estimator”(后面简称STE)的概念。我们可以将其简单理解为使用一个与$A$近似的$B$代表$A$进行运算从而达到我们预想的效果,比如量化。比如对于XNOR-Net而言STE就是以下的公式(没必要纠结于STE的概念,理解成计算的近似即可):
\[\begin{eqnarray} \textbf{Forward:}&& r_o = sign(r_i) \times \mathbf{E}_F(|r_i|)\\ \textbf{Backward:}&& \frac{\partial c}{\partial r_i} = \frac{\partial c}{\partial r_o} \end{eqnarray}\] 其中$r_o$是该层的输出;$r_i$是该层的输入;$\mathbf{E}_F(·)$是XNOR-Net中对于Feature Map进行量化时的操作函数,因为每一层的操作都不同,因此带有角标$F$。这里的STE就是将$r_i$使用STE变为$r_o$,从而forward和backward过程都采用$r_o$代替$r_i$进行计算。
开头我们强调过,本文可以将定点数量化为任意比特。但是本着前人栽树后人乘凉的原则,作者们借鉴了XNOR-Net的部分。所以将量化算法分成了两部分,分别采用不同的算法:
- 1-bit量化。
- k-bit量化。
1-bit量化对XNOR-Net进行了一点点的修改,所有层的Feature Map都采用同一个量化参数,也就是消除了不同层的$\mathbf{E}(·)$函数的区别,变成了下面的计算公式:
\[\begin{eqnarray} \textbf{Forward:}&& r_o = sign(r_i) \times \mathbf{E}(|r_i|)\\ \textbf{Backward:}&& \frac{\partial c}{\partial r_i} = \frac{\partial c}{\partial r_o} \end{eqnarray}\] 而对于k-bit($k > 1$)量化,作者采用了新的量化方式:
\(\begin{eqnarray} \textbf{Forward:}&& r_o = f_w^k(r_i) = 2quantize_k(\frac{tanh(r_i)}{2max(|tanh(r_i)|)} + \frac{1}{2}) - 1 \\ \textbf{Backward:}&& \frac{\partial c}{\partial r_i} = \frac{\partial c}{\partial r_o}\frac{\partial r_o}{\partial r_i} \end{eqnarray}\)
这里使用$tanh(·)$函数将输入$r_i$的范围放缩到$[-1,1]$范围内,$\frac{tanh(r_i)}{2max(|tanh(r_i)|)} + \frac{1}{2}$将结果又放缩到$[0, 1]$范围之内,然后$quantize_k(·)$函数将这个结果量化为$k$-bit的在$[0,1]$之间的定点小数,最后的仿射变换又将数字调整到$[-1,1]$范围之内。
这里之所以要进行如此多的放缩变化,我的理解是$\frac{tanh(r_i)}{2max(|tanh(r_i)|)}$在一个比$[0,1]$更大的范围内进行本层数据的放缩更不易丢失数据分布,然后放缩入$[0,1]$是一开始基础计算公式不允许出现负数,并且全为正数方便计算不需要处理正负号,最后量化之后放缩入$[-1,1]$是将数据变成zero-mean方便下一层的运算。
针对Activation的量化,文章中非常简洁:
\[f_\alpha^k (r) = quantize_k(r)\]Backward过程
对于backward过程而言,就是对梯度进行量化。在上面的forward过程中我们可以发现都是统一量化为1-bit或者k-bit,但是针对backward过程作者和Gupta等的文章“Deep learning with limited numerical precision”都发现随机梯度量化要好于确定性的统一量化。下面稍微解释一下:
梯度和weights的最大不同是:梯度是unbounded,而weights收缩在$[0,1]$之间。并且梯度有明显的层间不同性。既然是unbounded,那么按照确定化的办法进行量化显然是有问题的。所以文章中提出了稍微不同的量化办法:
\[\tilde{f}_\gamma^k (dr) = 2·max_o(|dr|)\left[quantize_k(\frac{dr}{2 max_o(|dr|)} + \frac{1}{2} + \frac{\sigma}{2^k-1}) - \frac{1}{2} \right]\] 其中$dr = \frac{\partial c}{\partial r}$,这个计算在forward部分已经提到了,因为整体都是对fix-point小数的量化,所以均可导;$\frac{\sigma}{2^k-1}$是加入梯度量化中的噪声用来弥补潜在的bias,$\sigma \sim Uniform(-0.5, 0.5)$,这个噪声的加入对于整体的训练过程的稳定性非常重要。
算法与代码

相关的算法部分代码请见:dorefa.py
结果分析
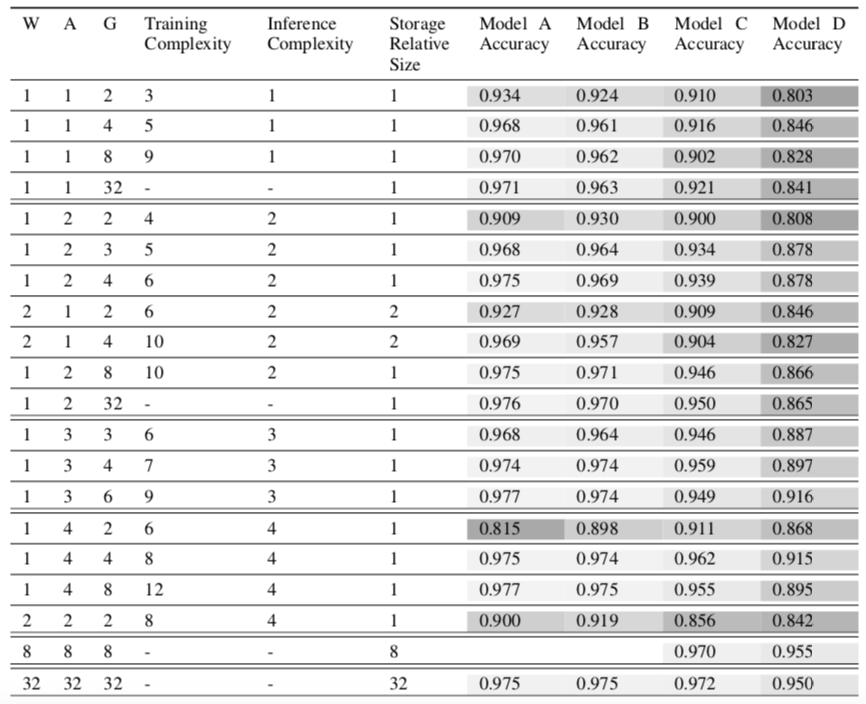
该表描述的是DoReFa在SVHN数据集上的表现,SVHN是一个实际中数字识别数据集。表中$W,A,G$分别代表weight/activation/gradient的bits数;其中的Model A的组成为:七层convolutional layer和一层fully-connected layer。Model B/C/D是从Model A中衍生出来的三个模型,相对于Model A分别将convolutional layer的channel数减少50%, 75%, 87.5%。
可以发现,全精度的网络准确率为0.975,而1-bit表示的weights和activation和2-bit表示的gradient准确率可以达到0.934;将gradient的bit数提高到4之后可以达到0.968的准确率。这里有一个比较有意思的现象,gradient的bits数对于准确率的影响要大于weights和activations的bits数的影响。
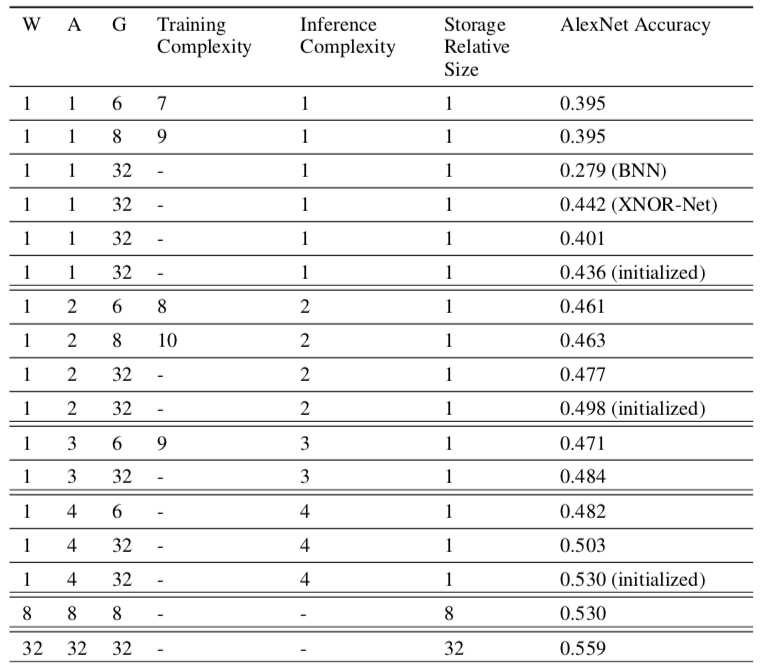
第二个表格描述的是将AlexNet用DoReFa算法进行量化,然后应用在ImageNet上的结果。这张图主要看和XNOR-Net的对比,提高为k-bit的时候相对于XNOR-Net有明显的提升;组合调整W/A/G三个参数,可以使用更少的bit总数但是达到了更好的效果。
总体来说,DoReFa能够提供组合优化的措施,使得W/A/G三个参数达到互相取值的一个相对XNOR-Net更优的解。但是这篇文章没有提到DoReFa的训练时间的对比,这是我们需要注意的一点,因为减少了整体的bits数并且有更高效的计算方法的前提下,运算效率应该会提升,也应该给在移动设备上训练创造了基础。