论文: Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
论文链接:https://arxiv.org/abs/1712.05877
在此之前一些压缩、量化方法的缺点:
- baseline使用的是AlexNet、VGG、GoogLeNet,这些网络为了最后的精度存在着大量的冗余,因此使用这些网络作为baseline表现自己的压缩率会有不错的提升。但是真正的难点是在轻量级网络上进行压缩,并取得比较高的准确率。
- 很多量化放大没有真正在硬件上进行有效性证明。
- 有的方法只在weight上量化,仅仅在乎在设备的存储,而不在乎计算效率。
- 有的方法把权重限制为0或者$2^n$,把乘法计算用bit-shift实现。但是在现有的硬件上,bit-shift运算效率相较**<乘法-加法>**并没有显著提高。因为只有当bit较大时乘法开销才会变大,所以需要将乘法的输入weight和activation都给量化成较小的bit。
这篇论文提出了在移动设备上进行高效inference的量化方案,该方案仅仅使用整数算法进行inference,该算法在通常可用的硬件上比浮点inference能更有效地实现。为了能够在精度和inference时间上进行权衡,本文还提出了一种量化训练方式,以保证量化后的端到端模型准确性。因此本文中值得关注的是以下几点:
- 如何对网络中不同区域的float参数分别进行量化。
- 量化对forward过程的影响:如何解决量化之后前后参数传递以及激活过程。
- 本文是对inference的量化,因此不设计对backward的影响。
量化算法
如下图所示,我们可以将量化需求分为三部分:
- 权重(kernel)部分。
- 激活(Activation)部分。
- 归一化(Batch Normalization)部分。
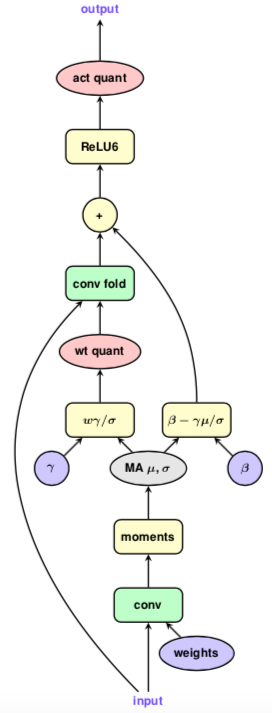
量化规则
本文中提出的量化的基础假设是:
\[r = S(q-Z)\]这个公式中$r$代表实数32-bit,$q$代表量化之后的整数8-bit;$S$代表量化中的伸缩变量为实数32-bit,$Z$代表量化值$q$和0之间的纠正差距,同样为8-bit。对于每一个layer采用同样一组<$S,Z$>。其中参数的计算公式如下:
\[\begin{eqnarray} S &=& \frac{W_{max} - W_{min}}{2^{bit\_width} - 1} \\ round(x) &=& \left\{ \begin{array}{l} 0, & x < 0 \\ [x], & 0\leq x < 2^{bits} - 1\\ 2^n - 1, & 2^n-1 \leq x \end{array} \right. \\ Z &=& round(-\frac{W_{min}}{S}) \\ q &=& round(Z + \frac{r}{S}) \end{eqnarray}\]我们可以发现,$S$其实就是针对当前权重矩阵的一个放缩变换,图像处理中所有像素的范围为$[0, 2^8-1]$。上述公式中$round(·)$操作里$[x]$代表距离$x$最近的整数。这里可以对上述量化公式做一个简单的验证计算:
\[\begin{eqnarray} q &=& round(Z + \frac{r}{S}) \\ &=& round(round(-\frac{W_{min}}{S}) + \frac{r}{S}) \\ &=& -\frac{W_{min}}{S} + \frac{r}{S} \\ &=& \frac{r - W_{min}}{S} \\ &=& \frac{r - W_{min}}{W_{max} - W_{min}}·(2^{bits} - 1) \end{eqnarray}\]其中第三行的条件为$0 \leq W_{min} < 2^n-1$。很明显可以看出:量化值$q$的计算就是对当前的值进行一个Max-min归一化然后扩展到$[0, 2^{bits}-1]$的过程。
以上是根据量化的算法进行单点运算的过程。但是在神经网络训练以及inference过程之中,全部都是矩阵运算,比如卷积操作就是两个矩阵相乘的过程,因此需要对上述的公式进行一个更加详细的推导以及扩展。
假设两个$N \times N$的实数矩阵相乘得到结果矩阵。第一个矩阵角标都为1,第二个矩阵角标都为2,结果矩阵的角标为3。即:$r_3 = r_1r_2$。那么在矩阵的表示中,最初的基础假设关系式就变成了:
\[r_{\alpha}^{(i,j)} = S_{\alpha} (q_{\alpha}^{(i,j)} - Z_{\alpha})\]那么对于矩阵相乘(这里对应卷积操作)我们就有以下的表示:
\[\begin{eqnarray} && S_3(q_3^{(i,k)} - Z_3) = \sum_{j=1}^N S_1(q_1^{(i,j)} - Z_1)S_2(q_2^{(j,k)} - Z_2) \\ \Rightarrow && q_3^{(i,k)} = Z_3 + {\color{red}M}\sum_{j=1}^N (q_1^{(i,j)} - Z_1)(q_2^{(j,k)} - Z_2) \end{eqnarray}\]这样就得到了更简便的计算方式:bit-shift变成了**<乘法-加法>**形式的计算。其中针对${\color{red}M}$我们再进行详细的讨论。根据计算过程我们很容易得到以下的表示:
\[\begin{eqnarray} M &=& \frac{S_1S_2}{S_3} \\ &=& (\frac{W^1_{max} - W^1_{min}}{2^{bits}-1} · \frac{W^2_{max} - W^2_{min}}{2^{bits}-1} )/(\frac{W^3_{max} - W^3_{min}}{2^{bits}-1}) \\ &=& \frac{1}{2^{bits} - 1} · \frac{(W^1_{max} - W^1_{min})(W^2_{max} - W^2_{min})}{W^3_{max} - W^3_{min}} \\ &=& \frac{1}{2^{bits} - 1} · M_0 \end{eqnarray}\]在预测时,权重矩阵的量化参数可以通过已有参数统计出来,比如在我们得到结果矩阵之后就可以得到$S_3$。而activation的量化是大量训练数据的指数移动均值统计出来的,接下来会讲到。
上式其中的$\frac{1}{2^{bits}-1}$可以近似表示成$2^{-bits}$,那么将M表示成一个归一化形式:$M = 2^{-bits}M_0$。经过大量的实验,文章中提到$M_0 \in [0.5, 1)$。这时的$M_0$计算可以按照fix-point乘法进行计算,最后和$2^{-bits}$相乘的时候可以使用bit-shift。但是在这里使用$round(·)$函数的时候会有精度的问题,比如计算$-12/2^3$的时候,采用文章的计算方法会出现最后的round结果为$-1$但是实际上应该是$-2$。这里出现问题的主要原因为:bit表示能力有限,纯bit算法类似于unsigned int计算很容易溢出,因此作者采用了将uint变为int然后进行zero-mean归一化就会很好地解决精度问题:
\[\begin{equation} int32 = int8 * int8 \end{equation}\]因为int8在进行乘法的时候需要进行操作数扩展,为了避免每次操作的时候都进行扩展,文中重写了结果$q_3$的计算:
\[q_3^{(i,k)} = Z_3 + M (NZ_1Z_2 - Z_1 \sum_{j=1}^N q_2^{(j,k)} - Z_2 \sum_{j=1}^N q_1^{(i,j)} + \sum_{j=1}^N q_1^{(i,j)}q_2^{(j,k)})\]其中一个$\sum$就只有N次加法,相对于原始计算方法减少了求和计算中的减法并且防止0的出现,因为在这样的量化算法中0是很难精确表示的。
训练过程
作者分析原有的量化方法:用floating-point训练,然后量化训练的weights(有时候会进行量化后的微调)。发现这种方法对于大模型来说结果不错,对小模型来说精确度下降不小。作者对这种量化后的微调方法分析了存在的两点问题:
- 同一layers不同channels权重分布尺度差很多(接近100倍)。
- 离散的权重会导致所有剩余的权重的精度下降。
作者提出了一种在前向传播阶段模拟量化的方法,反向传播和平常一样,所有的权重和biases都用floating point保存以微调小变化。前向传播的浮点数计算方法,模拟量化的方式。对每一层,数值都用参数(量化层次,和clamping range)量化:
\[clamp(r;a,b) = min(max(x,a),b) \\ s(a,b,n) = \frac{b-a}{n-1} \\ q(r;a,b,n) = [\frac{clamp(r;a,b) - a}{s(a,b,n)}]s(a,b,n) + a\]其中,$r$是待量化的实数;$[a,b]$是量化的范围;$n$是量化的等级数对所有layer都是固定的,比如8-bit量化,$n=2^8=256$。公式$clamp(·)$表示x所处的范围,即映射前的range,之所以有这个看起来没用的公式,是因为activation的range是使用EMA估计出来的;公式$s(·)$表示range映射到n-1段的时候每段的大小;公式$q(·)$表示一个实数$r$就近到能完整量化的实数,且$[\frac{clamp(r;a,b) - a}{s(a,b,n)}]$是能我们的B-bit表示的量化结果;bias没有被量化,因为在inference阶段用32-bit表示。
这里需要说一下我们一开始就针对一个block分为了:kernel、activation、batch normalizatio三部分,那么:
- 对于weight:$a = min(W), b = max(W)$。
- 对于activation:使用EMA收集activation的范围$[a,b]$,平滑参数接近1。(若范围快速变化时,指数移动平均会延迟反映出来,所以在训练初期(5万步到200万步)时可以禁止activation的量化。)
- 对于Batch Normalization:使用EMA收集activation的范围$[a,b]$。
Batch Normalization是一个比较特殊的存在,它独立于卷机和激活层,因此需要单独处理。这篇文章中将BN直接嵌入到了卷机操作的结果之后:
\[W_{BN} = \frac{\gamma W}{\sqrt{EMA(\sigma_{B}^2) + \epsilon}}\]其中$\gamma$是Batch Normalization的放缩常量,是一个超参数;$EMA(\sigma_B^2)$是整个Batch中卷积结果方差的移动平均值估计。
结果分析
本文的结果分析主要集中在对目前常用网络:ResNet,InceptionNet-v3,MobileNet。
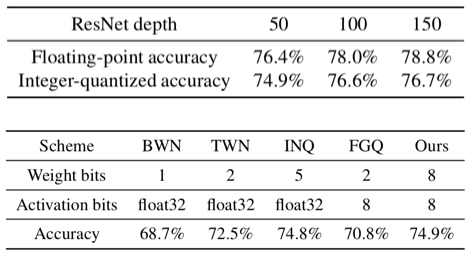
这张表反映的是QAT量化方法在ResNet在ImageNet数据集上的效果,与全精度网络的Top-1 accuracy不相上下,差距均小于2%;和其他量化方法相比,准确率提升非常之大。
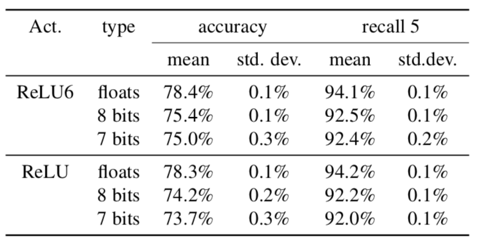
这张表反映的是QAT量化方法在InceptionNet-v3在ImageNet数据集上的效果,可以发现效果也非常好。
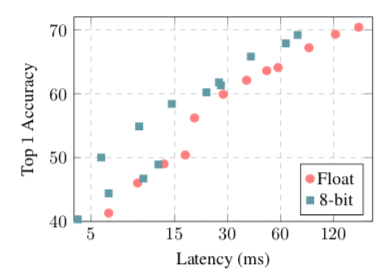
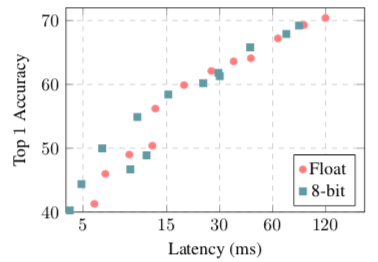
上面两张图,左边为在高通骁龙835上的实验结果,右边为在高通骁龙821上的实验结果。可以发现在移动设备的inference准确度上和全精度网络也不相上下。