论文:EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
论文链接:https://arxiv.org/abs/1905.11946
代码链接:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
第三方实现的PyTorch代码:https://github.com/lukemelas/EfficientNet-PyTorch
Google发布在ICML2019的论文对目前分类网络的优化提出更加泛化的思想,认为目前常用的加宽网络、加深网络和增加分辨率这3种常用的提升网络指标的方式之间不应该是相互独立的。因此提出了compound model scaling算法,通过综合优化网络宽度、网络深度和分辨率达到指标提升的目的,能够达到准确率指标和现有分类网络相似的情况下,大大减少模型参数量和计算量。重要应用是通过优化本身参数量都很少的模型,让这样的模型达到像ResNet这种庞大参数数量模型的精度。
网络 Width:kernel数量
网络 Depth:模型的层数
Resolution:输入图像的分辨率大小
基础网络
MobileNet-v1:是将三维卷积拆分成depth wise$1\times 1$卷积和point wise的平面$3\times 3$卷积。
MobileNet-v2:
- Linear Bottlenecks:将每一个stage模块化,如果该模块的输入维度为m,输出维度为n,且$m \leq n$,那么输出维度可以在保证精度的前提下被压缩到输入维度的厚度。
- Inverted residuals:每一个stage根据Linear Bottlenecks将输入输出维度缩小,让中间特征提取维度扩大,这样既能保证最大限度进行特征提取,又能使运算量下降。
基础的网络优化算法都只是基于单一的宽度(比如MobileNet,Inception-Net等)、深度(ResNet等)、分辨率(MobileNet为主,也有通过提高原始图像精度提高网络准确率的办法)。
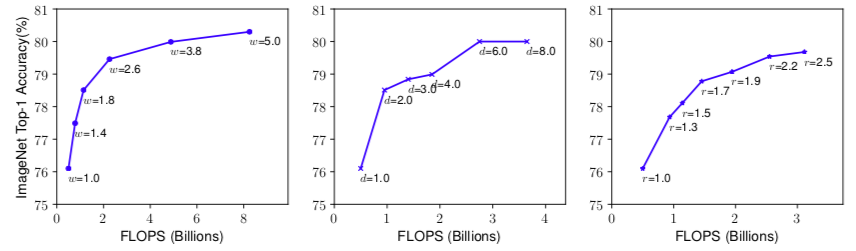
上图描述了扩展具有不同网络宽度(w),深度(d)和分辨率(r)系数的baseline模型。 具有更大宽度,深度或分辨率的更大网络倾向于实现更高的准确度,但是在达到80%之后准确度增益快速饱和,证明了单维缩放的确有很大的限制性。也就是上面每一种调整模型的办法一开始让整体模型的准确率提升上去了,但对于不断调整过程中模型变大,精度增益会降低。
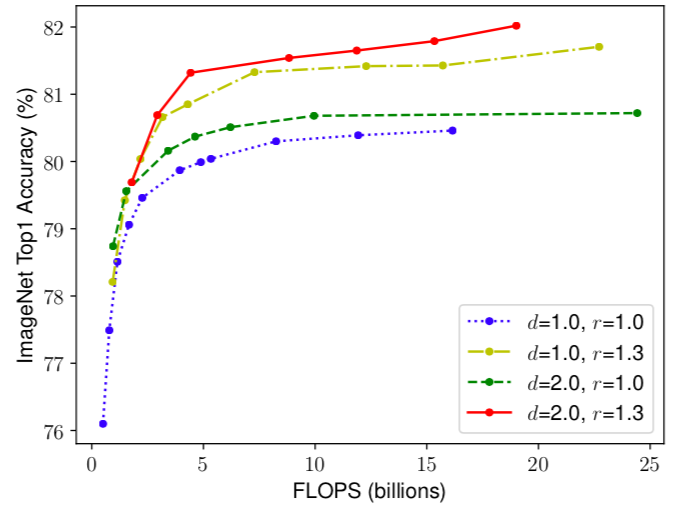
上图描述了同时调整深度和分辨率对网络性能的影响,线中的每个点表示具有不同宽度系数(w)的模型。 所有baseline网络均来自类似MnasNet结构(d = 1.0,r = 1.0)有18个卷积层,分辨率为224x224,而最后一个baseline(d = 2.0,r = 1.3)有36层,分辨率为299x299。因此,同时修改这些参数能够让网络性能上升到其余单一调整网络的性能,并且同时调整w,r,d会让小参数网络达到多参数网络的性能甚至超越。
建模
首先需要建立数学模型:
输入$X$大小为$<H, W, C>$,分别代表图像分辨率的高与宽以及channel数量,一个卷积神经网络可以看作一个函数$\mathcal{F}$,该层神经网络的输出就是$Y = \mathcal{F}(X)$,整个神经网络堆叠起来用$\mathcal{N}$表示。下面的公式表示:在保证内存使用上限以及运算量上限的前提下,使得当前网络能够得到d,w,r的调整使得在基础网络的基础上达到最大的准确率。

文中的一大要求是:我们当前的环境中内存大小是M,我们要求的运算次数是F,那么最后得到的模型不能超过我们的限制,这样的优化办法让神经网络能在小内存以及要求运算量少的平台上有用武之地,并且精度还很高。
网络结构
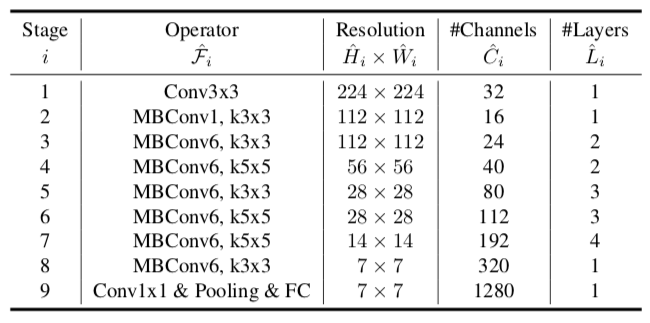
这里是整个Efficient Net的基础网络结构,这一个基础的网络叫做EfficientNet-B0.后面所有的实验中EfficientNet都是基于这个网络结构只是改变了d,w,r三个参数。
搜索最优参数的算法:
-
使用网格搜索办法,优化目标是$ACC(m) \times [FLOPS (m)/T]^w$,其中$ACC$代表模型的准确率,$FLOPS$代表计算复杂度,$T$代表目标复杂度,也就是复杂度上限,$w$代表一个控制$ACC$和$FLOPS$之间trade-off的参数。该公式表达的是在能够保证准确率的前提下尽可能减少计算复杂度。
-
网格搜索:一种调参手段。在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。其原理就像是在数组里找最大值。(为什么叫网格搜索?以有两个参数的模型为例,参数a有3种可能,参数b有4种可能,把所有可能性列出来,可以表示成一个3*4的表格,其中每个cell就是一个网格,循环过程就像是在每个网格里遍历、搜索,所以叫grid search)。下面是一个网格搜索的例子,也就是测试出来最优的参数,或者是接近最优的参数,暴力穷举。
-
for gamma in [0.001,0.01,0.1,1,10,100]: for C in [0.001,0.01,0.1,1,10,100]: svm = SVC(gamma=gamma,C=C)#对于每种参数可能的组合,进行一次训练; svm.fit(X_train,y_train) score = svm.score(X_test,y_test) if score > best_score:#找到表现最好的参数 best_score = score best_parameters = {'gamma':gamma,'C':C}
-
该网络一共有18层,有5.3M参数,相比ResNet-50的26M参数减少很多。
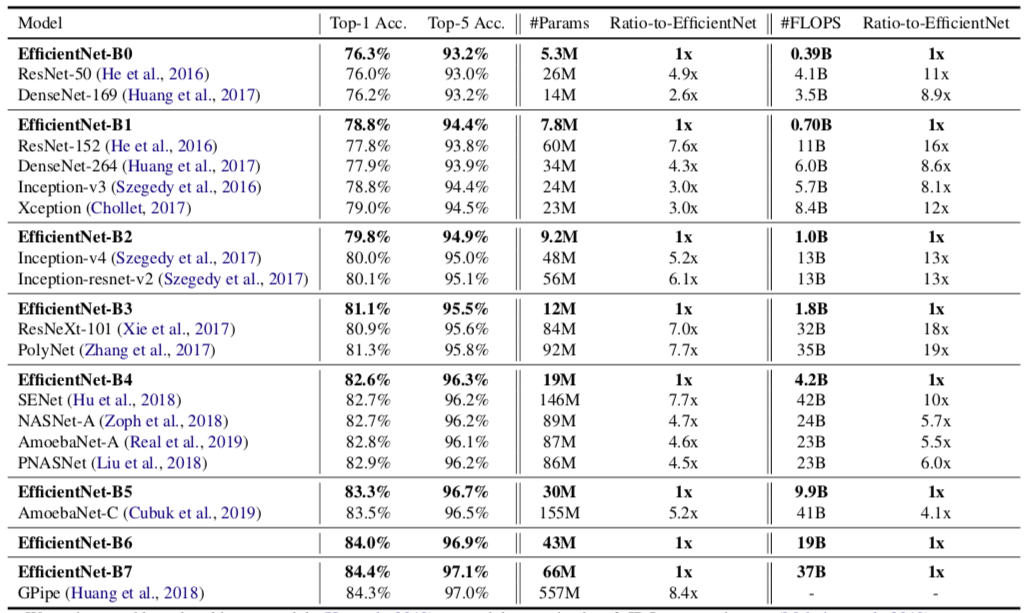
从上表可以看出,基础网络结构只有18层,准确率能够超过ResNet-50。但是ResNet-50的参数量是B0网络的4.9倍,运算量是B0网络的10.5倍。
在进行网络优化的时候,需要平衡d,w,r三个参数,因此文中又提出了针对三者调整关系的定义:
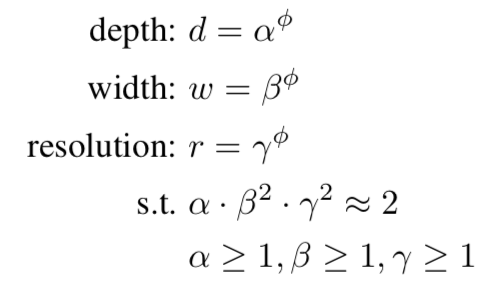
其中$\alpha, \beta, \gamma$分表代表了深度、宽度、分辨率的基础数值,$\phi$代表对三个基础数值的调整系数。其中要求$\alpha \cdot \beta^2 \cdot \gamma^2 \approx 2$是保证整体的运算复杂度,不能超过原始运算复杂度的两倍。
B0网络的三个参数分别为:α = 1.2, β =1.1,γ=1.15,这是通过网格搜索算法得到的最优参数。
整个实验过程文章中给出了B0~B7一共8个模型,通过如下的步骤确定:
- STEP-1:固定调整参数$\phi=1$,假定可用资源是原始模型所需资源的两倍,也就是$\alpha \cdot \beta^2 \cdot \gamma^2 \approx 2$。然后通过网格搜索的到B0网络的参数α = 1.2, β =1.1,γ=1.15。
- STEP-2:我们得到三个参数之后,在后面的调整之中固定α = 1.2, β =1.1,γ=1.15,调整$\phi$的数值,然后得到网络B1~B7.
从下右图可以看出,使用Efficient Net的方法将一个18层的网络能够性能调优到和比其参数多数十倍的模型一样的精度。
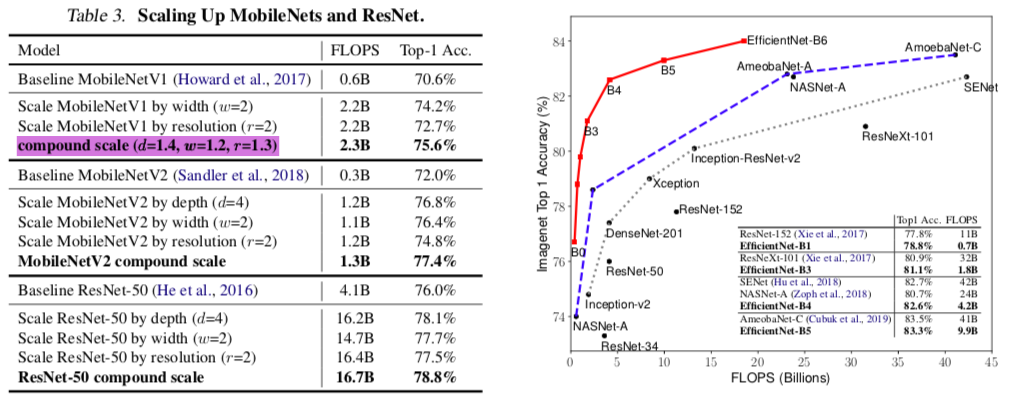
上表是基于MobileNet和ResNet调整出来的模型,可以发现,在没有提高计算量的前提下,通过整体模型d,w,r的比例调整,可以显著提升整体网络的性能。
还有比较关心的一点是,参数α = 1.2, β =1.1,γ=1.15,其中$\beta$和$\gamma$分别控制网络的filter数量以及输入图像分辨率的大小,原始的w和r两个参数数量级在百以上,因此1.1以及1.15能够得到整数. $\alpha$控制网络的深度,基础网络的深度是18层,18*1.2=21.6,在这种情况下,需要尝试最后网络的深度是21层还是22层。