论文:XNOR Net: ImageNet Classification Using Binary Convolutional Neural Networks
论文地址:https://arxiv.org/abs/1603.05279
代码地址:http://allenai.org/plato/xnornet
针对神经网络的二值化,一共就三个方面:
-
整个网络架构的层的表示,如何二值化,比如卷积层,激活层,BN层。
- 网络的运算与传播更新如何在二值化的表示之下进行:
- Forward Pass
- Backward Pass
- Parameters Updates
-
如何在模型缩减情况下提高精度。
- kernel都是正负1,这样整个卷积过程都是+/-,没有了乘法。正负1可以用一个bit进行表示,因此memory占用减少了32x
- 将权重矩阵二值化,但是为什么优化B和$\alpha$的时候,还有权重矩阵W出现在结果里,W是float更新的。
- 软件实现(使用tensorflow / torch等)并不能减小整体模型的大小,如果想要减小整体模型的大小,需要修改深度学习框架(甚至需要修改cuda lib),因此软件实现只能验证XNOR-Net的理论正确性,但是并不能实现文章中提到的32x模型大小的缩减。但是如果从硬件层面进行实现的话,应该可以达到文章中所述的模型size缩减的比例。
二值化表示
首先是权重矩阵的二值化,因为普通的二值化过程直接将权重矩阵zero-centered为{-1, 1}让整体的精度损失非常大,因此文章中在二值化的时候增加了一个scaling ratio:$\alpha$,假设输入的tensor为$I$,输入的矩阵为$W$,之前直接让$W \approx B$,在XNOR-Net中,$W \approx \alpha B$,那么整个的卷积操作为:
\[\begin{equation} I * W \approx (I \oplus B)\alpha \end{equation}\]其中,$\oplus$表示没有乘法的卷积操作,因为针对binary值{-1, 1}而言,直接进行+/-即可。这样可以大大减小运算的开销。现在,每次可以在进行权重二值化的时候,使用符号函数$sign(W)$进行$W \rightarrow B$的映射,为了能够让精度更高、信息损失更少,需要一个精确的$\alpha$。
因为我们的二值化目标是让信息损失最少,也就是尽可能让$W$与$\alpha B$接近,衡量这种距离,文章中使用了二范数(欧式距离)。
\[\begin{equation} J(B, \alpha) = || W - \alpha B ||^2 \\ \alpha^{*}, B^* = argmin_{\alpha, B} J(B, \alpha) \end{equation}\]将其展开就是:
\[\begin{equation} J(B, \alpha) = \alpha^2 B^TB - 2\alpha W^TB + W^TW \end{equation}\]其中,$\alpha, B^TB, W^TW$都是constant,求解$\alpha$就可以使用求导得到$J’_{\alpha} = 2B^TB\alpha - 2W^TB$,令这个式子为0.
那么我们可以得到:
\[\begin{equation} \alpha = \frac{W^T B}{B^TB} = \frac{W^T sign(W)}{B^TB} = \frac{\sum |W_i|}{B^TB} = \frac{||W||_{l_1}}{B^TB} \end{equation}\]最后就可以得到最优的$\alpha$。
接下来就是将特征tensor进行二值化。整体的二值化过程相同,使用符号函数$sign(X)$得到$H$,然后使用一个$\beta$参数进行精度调整。这样每个layer的运算$X^TW \approx \beta H^T \alpha B$,其中$H,B \in {-1, 1}, \alpha, \beta \in R^+$。
针对特征tensor的二值化,如果在运算过程之中进行二值化,由于卷积的shift过程有重叠,会造成重复运算scaling factor,因此文章中采用了直接整体二值化的措施。采用:
\[\begin{equation} A = \frac{\sum|I_{:, :, c}|}{c} \end{equation}\]将整个三维特征矩阵压缩成二维特征,然后用二维的filter $k$进行卷积得到一个二维矩阵$K$,其中$k = \frac{1}{w \times h}$,并且$K$就是包含着对每个channel进行scaling的参数$\beta$。针对输入矩阵$I$的二值化同样采用符号函数$sign(I)$。这样我们就得到了双重二值化的卷积操作公式:
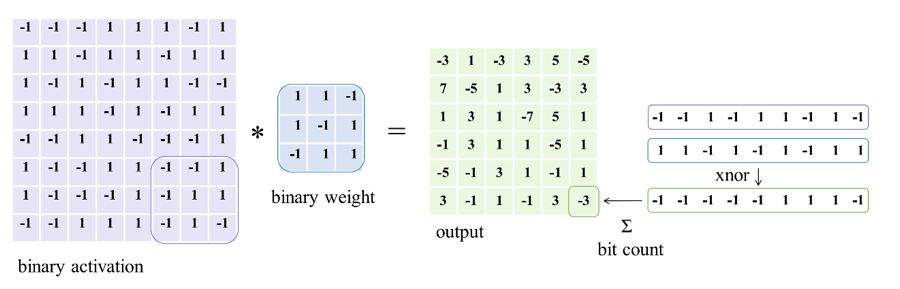
\[\begin{equation} I* W \approx (sign(I) \otimes sign(W)) \odot K\alpha \end{equation}\]其中$\otimes$是由XNOR(同或)操作实现的卷积操作。因为针对{-1, 1}而言,两个乘数相同结果为1,不同结果为-1,所以可以直接使用同或进行卷积操作,大大降低了运算开销。Xnor-Net的运算操作如下图所示:
梯度更新
在XNOR-Net中,只在forward pass和backward propagation中进行权重的二值化,在进行参数更新的时候,需要采用原始bit数目的浮点数。因为在训练的时候,每次修正的梯度都非常小,因此如果采用量化的办法,每次的真实权重参数的变化几乎都为0,量化过程消除了梯度的更新。
Forward Pass
原始权重 $\mathbf{W}$ :$\mathbf{W}=[W_{1},W_{2}, …, W_{n}] $
In the forward pass:我们需要二值化 $\mathbf{W}$ 到 $\mathbf{\widetilde{W}}$ :
\[\begin{equation} \mathbf{\widetilde{W}}=[\widetilde{W}{1},\widetilde{W}{2}, ..., \widetilde{W}{n}] \end{equation}\]根据文章中,二值化的权重矩阵 $\mathbf{\widetilde{W}}$ 的计算公式为:
\[\begin{equation} \mathbf{\widetilde{W}}=\alpha \cdot sign(\mathbf{W}) \\ \alpha = \frac{1}{n} \cdot {||\mathbf{W}||}{L1} = \frac{1}{n} \cdot \sum{i=1}^{n} |W{i}| \end{equation}\]也就是对于每一个 $\widetilde{W}_{i}$,都有:
\[\begin{equation} \widetilde{W}{i} =\alpha \cdot sign(W{i}), \; i \in \{1,2,...,n\} \end{equation}\]这就是 the scaled sign function.
Backward Propagation
假定 $C$ 是 cost function, 根据paper描述 the scaled sign function的反向传播梯度是:
\[\begin{equation} \frac{\partial C}{\partial W{i}} = \frac{\partial C}{\partial \widetilde{W}{i}} (\frac{1}{n}+\frac{\partial sign(W{i})}{\partial W{i}} \cdot \alpha) \end{equation}\]由以下公式计算:
\[\begin{equation} \frac{\partial C}{\partial W{i}} = \frac{\partial C}{\partial \widetilde{W}{i}} \cdot \frac{\partial \widetilde{W}{i}}{\partial W{i}} \end{equation}\]计算细节为:
\[\begin{equation} \frac{\partial C}{\partial W{i}} = \frac{\partial C}{\partial \widetilde{W}{i}} \cdot \frac{\partial \widetilde{W}{i}}{\partial W{i}}\ \\ = \frac{\partial C}{\partial \widetilde{W}{i}} \cdot \frac{\partial (\alpha \cdot sign(W{i}))}{\partial W{i}}\ \\ = \frac{\partial C}{\partial \widetilde{W}{i}} \cdot [sign(W{i})\cdot\frac{\partial \alpha}{\partial W{i}} + \alpha \cdot \frac{\partial sign(W{i})}{\partial W{i}}]\ \\ = \frac{\partial C}{\partial \widetilde{W}{i}} [\frac{1}{n}+\frac{\partial sign(W{i})}{\partial W_{i}} \cdot \alpha] \\ \end{equation}\]这里对sign函数的导数,采用的是clip(-1,x,1)函数。
一旦训练完成,就没有必要保存真实的权重值了,因为在推理阶段我们只需要二值化权重来完成前向传播。inference过程就是一个forward pass过程。